







How AI Audio Data Collection Is Transforming Voice Assistants and Chatbots
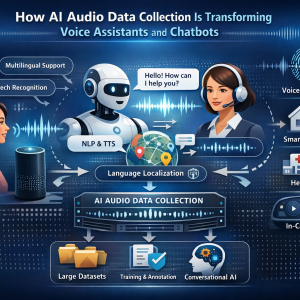
Voice technology has quickly become a natural way for people to interact with digital systems. From asking smart speakers about the weather to speaking with customer support chatbots, voice-driven experiences are now part of everyday life. Behind this rapid transformation lies one crucial component: AI Audio Data Collection.
Artificial intelligence systems that understand human speech require massive volumes of audio data. These datasets allow machines to recognize accents, interpret context, and respond to spoken commands accurately. Without structured Audio Data Collection, voice assistants and conversational chatbots would struggle to understand the diversity of human speech.
As businesses invest in conversational AI technologies, the demand for high-quality voice datasets continues to grow. Companies across industries,from banking and healthcare to e-commerce and smart home technology—are relying on AI-driven voice systems to improve customer experiences.
This article explores how AI Audio Data Collection is transforming voice assistants and chatbots, why voice datasets are critical for training conversational AI, and how language diversity and localization challenges shape the future of voice technology.
The Rise of Voice Interfaces
Over the last decade, voice interfaces have moved from experimental technology to mainstream digital interaction.
Today, millions of users interact daily with voice-powered systems through smartphones, smart speakers, and connected devices. This growth is largely driven by advancements in AI Audio Data Collection, which has enabled AI models to learn from vast libraries of speech samples.
Several factors explain the rise of voice interfaces:
- Increased adoption of smart devices
- Improvements in speech recognition technology
- Growing demand for hands-free interactions
- Integration of AI in customer service systems
Voice assistants can now perform tasks such as scheduling appointments, controlling smart home devices, and answering complex questions.
However, these capabilities are only possible when AI systems are trained with large speech datasets generated through AI Audio Data Collection processes.
Why Voice Datasets Are Essential for AI
Speech recognition and conversational AI rely entirely on audio training data. Voice datasets allow machines to understand pronunciation patterns, speech speed, background noise, and emotional tone.
A well-structured AI Audio Data Collection strategy ensures that datasets represent real-world conversations.
Key Elements of High-Quality Voice Datasets
|
Dataset Feature |
Why It Matters |
|
Accent Diversity |
Helps AI understand global users |
|
Background Noise |
Prepares AI for real environments |
|
Speech Speed Variations |
Improves recognition accuracy |
|
Language Variety |
Supports multilingual applications |
|
Emotional Tone |
Helps AI detect user sentiment |
Without diverse datasets, voice assistants would struggle to understand users with different accents or speaking styles.
Modern conversational systems rely on AI Audio Data Collection to build speech recognition models capable of handling millions of real-world voice interactions.
How AI Audio Data Collection Trains Conversational AI
Conversational AI systems such as chatbots and voice assistants rely on several machine learning models trained with audio datasets.
These models include:
- Automatic Speech Recognition (ASR)
- Natural Language Processing (NLP)
- Text-to-Speech (TTS) systems
Each of these technologies requires carefully collected speech data.
Through AI Audio Data Collection, voice recordings are gathered from speakers across different demographics, languages, and environments. These recordings are then transcribed and labeled to train machine learning models.
Speech Recognition Training
Audio recordings are used to train models that convert spoken words into text.
Intent Recognition
Once speech is converted to text, AI models analyze the meaning behind the words to identify user intent.
Response Generation
Chatbots or voice assistants generate responses based on the detected intent and conversation context.
The entire conversational pipeline relies on large volumes of speech samples created through AI Audio Data Collection.
Language Localization Challenges in Voice AI
One of the biggest challenges in building global voice assistants is language diversity.
Human speech varies significantly across regions due to accents, dialects, slang, and pronunciation differences. For voice AI to perform accurately worldwide, datasets must include diverse speech patterns.
This makes AI Audio Data Collection particularly complex.
Accent Variation
English spoken in India, the United Kingdom, and the United States differs significantly. Voice datasets must include these variations.
Multilingual Support
Many AI systems must understand multiple languages and switch between them seamlessly.
Cultural Context
Certain phrases or expressions may have different meanings across cultures.
To address these challenges, voice datasets collected through AI Audio Data Collection must include contributors from multiple regions and linguistic backgrounds.
Real-World Applications of Voice Assistants and Chatbots
Voice technology is transforming many industries.
Organizations are increasingly adopting conversational AI powered by AI Audio Data Collection to improve efficiency and customer engagement.
Customer Support Automation
Voice chatbots handle customer queries without human intervention, reducing support costs.
Smart Home Devices
Voice assistants allow users to control lights, thermostats, and appliances using simple voice commands.
Healthcare Assistance
Voice AI helps patients schedule appointments and receive medication reminders.
Automotive Systems
Modern vehicles include voice-controlled navigation and infotainment systems.
Banking and Financial Services
Banks use voice authentication and conversational chatbots to assist customers securely.
All these applications depend heavily on large speech datasets produced through AI Audio Data Collection.
Managing and Processing Audio Datasets
As voice datasets grow larger, managing them becomes increasingly complex.
Organizations involved in AI Audio Data Collection must establish strong data infrastructure to handle storage, processing, and labeling.
Audio Storage
Voice datasets can contain thousands of hours of recordings. Cloud storage systems are commonly used to manage this scale.
Metadata Tagging
Each audio file should include metadata such as language, speaker demographics, environment type, and recording conditions.
Data Annotation
Audio recordings are transcribed and labeled to help AI models understand the relationship between speech and meaning.
Quality Assurance
Quality checks ensure recordings are clear, properly labeled, and free from technical errors.
Effective dataset management ensures that